sub computeAverage # (table, context, aggop, opcode, rh, state, args...)
{
my ($table, $context, $aggop, $opcode, $rh, $state, @args) = @_;
# don't send the NULL record after the group becomes empty
return if ($context->groupSize()==0
|| $opcode != &Triceps::OP_INSERT);
my $sum = 0;
my $count = 0;
for (my $rhi = $context->begin(); !$rhi->isNull();
$rhi = $context->next($rhi)) {
$count++;
$sum += $rhi->getRow()->get("price");
}
my $rLast = $context->last()->getRow() or die "$!";
my $avg = $sum/$count;
my $res = $context->resultType()->makeRowHash(
symbol => $rLast->get("symbol"),
id => $rLast->get("id"),
price => $avg
) or die "$!";
$context->send($opcode, $res) or die "$!";
}
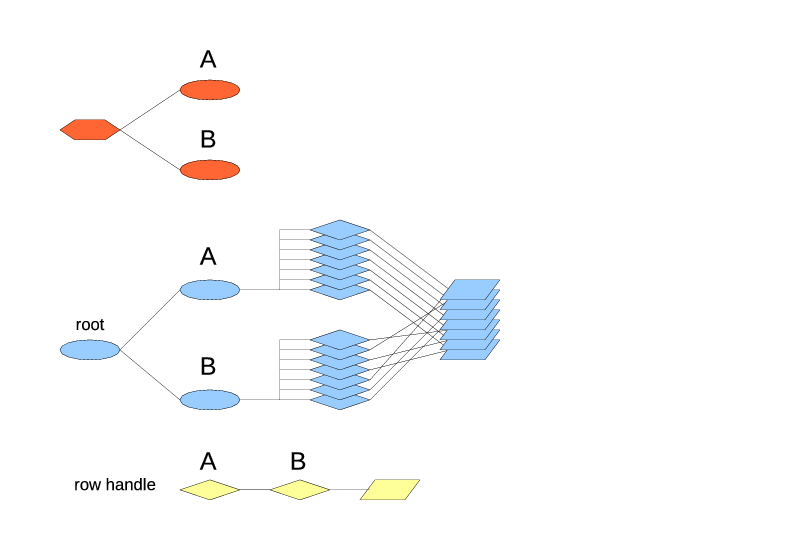
my $ttWindow = Triceps::TableType->new($rtTrade)
->addSubIndex("byId",
Triceps::IndexType->newHashed(key => [ "id" ])
)
->addSubIndex("bySymbol",
Triceps::IndexType->newHashed(key => [ "symbol" ])
->addSubIndex("last4",
Triceps::IndexType->newFifo(limit => 4)
->setAggregator(Triceps::AggregatorType->new(
$rtAvgPrice, "aggrAvgPrice", undef, \&computeAverage10)
)
)
)
or die "$!";
...
my $lbAverage = $uTrades->makeLabel($rtAvgPrice, "lbAverage",
undef, sub { # (label, rowop)
printf("%.17g\n", $_[1]->getRow()->get("price")));
}) or die "$!";
$tWindow->getAggregatorLabel("aggrAvgPrice")->chain($lbAverage)
or die "$!";
The differences from the previously shown basic aggregation are:
- the FIFO limit has been increased to 4
- the only result value printed by the lbAverage handler is the price, and it's printed with a higher precision to make the difference visible
- the aggregator computation only does the inserts, to reduce the clutter in the results.
And here is an example of how the order matters:
OP_INSERT,1,AAA,1,10 1 OP_INSERT,2,AAA,1,10 1 OP_INSERT,3,AAA,1,10 1 OP_INSERT,4,AAA,1e16,10 2500000000000001 OP_INSERT,5,BBB,1e16,10 10000000000000000 OP_INSERT,6,BBB,1,10 5000000000000000 OP_INSERT,7,BBB,1,10 3333333333333333.5 OP_INSERT,8,BBB,1,10 2500000000000000
Of course, the real prices won't vary so wildly. But the other values could. This example is specially stacked to demonstrate the point. The final results for AAA and BBB should be the same but aren't. Why? The precision of the 64-bit floating-point numbers is such that as adding 1 to 1e16 makes this 1 fall beyond the precision, and the result is still 1e16. On the other hand, adding 3 to 1e16 makes at least a part of it stick. 1 still falls of but the other 2 of 3 sticks. Next look at the data sets: if you add 1e16+1+1+1, that's adding 1e16+1 repeated three times, and the result is still the same unchanged 1e16. But if you add 1+1+1+1e16, that's adding 3+1e16, and now the result is different and more correct. When the averages get computed by dividing the sums by 4, the results are still different.
Overall the rule of thumb for adding the floating point numbers is this: add them up in the order from the smallest to the largest. (What if the numbers can be negative too? I don't know, that goes beyond my knowledge of floating point calculations. My guess is that you still arrange them in the ascending order, only by the absolute value.) So let's do it in the aggregator.
our $idxByPrice;
sub computeAverage # (table, context, aggop, opcode, rh, state, args...)
{
my ($table, $context, $aggop, $opcode, $rh, $state, @args) = @_;
our $idxByPrice;
# don't send the NULL record after the group becomes empty
return if ($context->groupSize()==0
|| $opcode != &Triceps::OP_INSERT);
my $sum = 0;
my $count = 0;
my $end = $context->endIdx($idxByPrice);
for (my $rhi = $context->beginIdx($idxByPrice); !$rhi->same($end);
$rhi = $rhi->nextIdx($idxByPrice)) {
$count++;
$sum += $rhi->getRow()->get("price");
}
my $rLast = $context->last()->getRow() or die "$!";
my $avg = $sum/$count;
my $res = $context->resultType()->makeRowHash(
symbol => $rLast->get("symbol"),
id => $rLast->get("id"),
price => $avg
) or die "$!";
$context->send($opcode, $res) or die "$!";
}
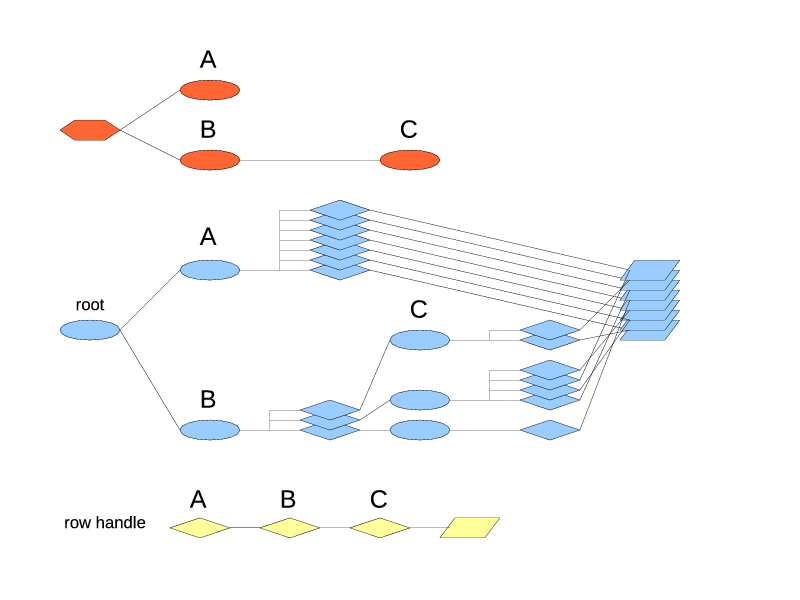
my $ttWindow = Triceps::TableType->new($rtTrade)
->addSubIndex("byId",
Triceps::IndexType->newHashed(key => [ "id" ])
)
->addSubIndex("bySymbol",
Triceps::IndexType->newHashed(key => [ "symbol" ])
->addSubIndex("last4",
Triceps::IndexType->newFifo(limit => 4)
->setAggregator(Triceps::AggregatorType->new(
$rtAvgPrice, "aggrAvgPrice", undef, \&computeAverage11)
)
)
->addSubIndex("byPrice",
Triceps::SimpleOrderedIndex->new(price => "ASC",)
->addSubIndex("multi", Triceps::IndexType->newFifo())
)
)
or die "$!";
$idxByPrice = $ttWindow->findSubIndex("bySymbol")
->findSubIndex("byPrice") or die "$!";
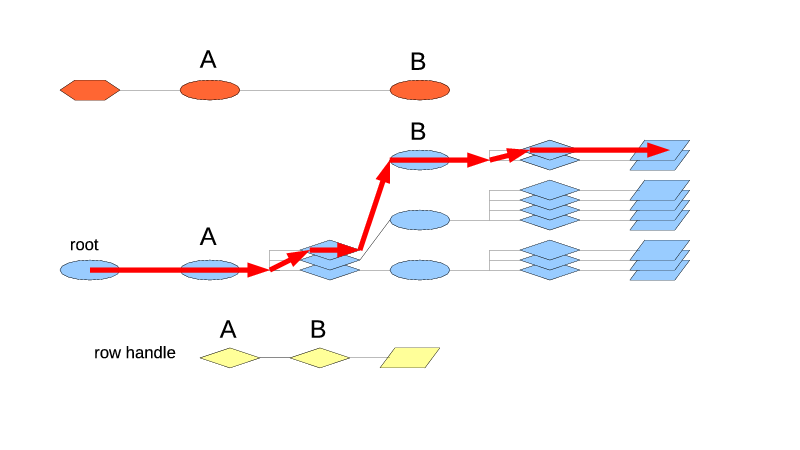
Here another index type is added, ordered by price. It has to be non-leaf, with a FIFO index type nested in it, to allow for multiple rows having the same price in them. That would work out more efficiently if the ordered index could have a multimap mode, but that is not supported yet.
When the compute function does its iteration, it now goes by that index. The aggregator can't be simply moved to that new index type, because it still needs to get the last trade id in the order the rows are inserted into the group. Instead it has to work with two index types: the one on which the aggregator is defined, and the additional one. The calls for iteration on an additional index are different. $context->beginIdx() is similar to $context->begin() but the end condition and the next step are done differently. Perhaps the consistency in this department can be improved in the future.
And finally, the reference to that additional index type has to make it somehow into the compute function. It can't be given as an argument because it's not known yet at the time when the aggregator is constructed (and no, reordering the index types won't help because the index types are copied when connected to their parents, and we need the exact index type that ends up in the assembled table type). So a global variable $idxByPrice is used. The index type reference is found and placed there, and later the compute function takes the reference from the global variable.
The printout from this version on the same input is:
OP_INSERT,1,AAA,1,10 1 OP_INSERT,2,AAA,1,10 1 OP_INSERT,3,AAA,1,10 1 OP_INSERT,4,AAA,1e16,10 2500000000000001 OP_INSERT,5,BBB,1e16,10 10000000000000000 OP_INSERT,6,BBB,1,10 5000000000000000 OP_INSERT,7,BBB,1,10 3333333333333334 OP_INSERT,8,BBB,1,10 2500000000000001
Now no matter what the order of the row arrival, the prices get added up in the same order from the smallest to the largest and produce the same correct (inasmuch the floating point precision allows) result.
Which index type is used to put the aggregator on, doesn't matter a whole lot. The computation can be turned around, with the ordered index used as the main one, and the last value from the FIFO index obtained with $context->lastIdx():
our $idxByOrder;
sub computeAverage12 # (table, context, aggop, opcode, rh, state, args...)
{
my ($table, $context, $aggop, $opcode, $rh, $state, @args) = @_;
our $idxByOrder;
# don't send the NULL record after the group becomes empty
return if ($context->groupSize()==0
|| $opcode != &Triceps::OP_INSERT);
my $sum = 0;
my $count = 0;
for (my $rhi = $context->begin(); !$rhi->isNull();
$rhi = $context->next($rhi)) {
$count++;
$sum += $rhi->getRow()->get("price");
}
my $rLast = $context->lastIdx($idxByOrder)->getRow() or die "$!";
my $avg = $sum/$count;
my $res = $context->resultType()->makeRowHash(
symbol => $rLast->get("symbol"),
id => $rLast->get("id"),
price => $avg
) or die "$!";
$context->send($opcode, $res) or die "$!";
}
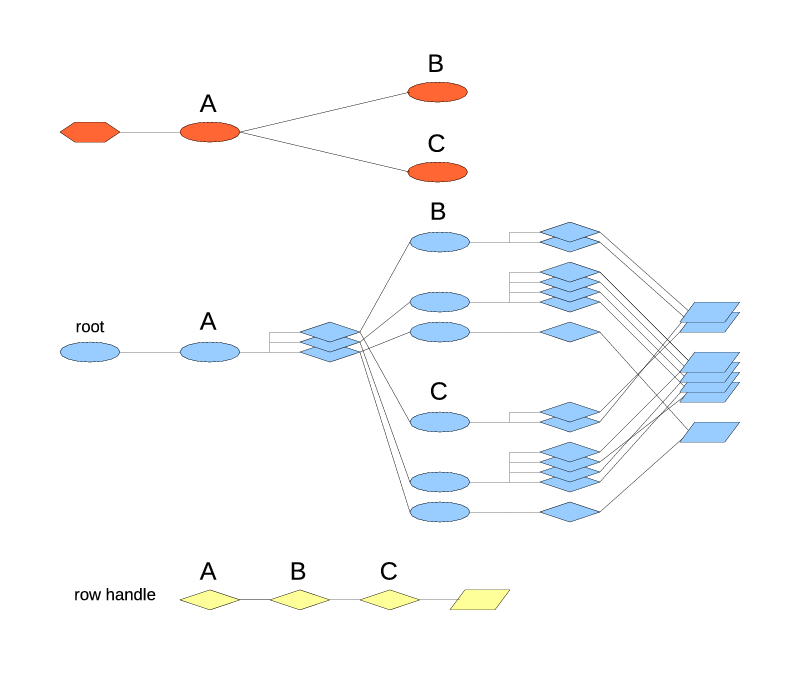
my $ttWindow = Triceps::TableType->new($rtTrade)
->addSubIndex("byId",
Triceps::IndexType->newHashed(key => [ "id" ])
)
->addSubIndex("bySymbol",
Triceps::IndexType->newHashed(key => [ "symbol" ])
->addSubIndex("last4",
Triceps::IndexType->newFifo(limit => 4)
)
->addSubIndex("byPrice",
Triceps::SimpleOrderedIndex->new(price => "ASC",)
->addSubIndex("multi", Triceps::IndexType->newFifo())
->setAggregator(Triceps::AggregatorType->new(
$rtAvgPrice, "aggrAvgPrice", undef, \&computeAverage12)
)
)
)
or die "$!";
$idxByOrder = $ttWindow->findSubIndex("bySymbol")
->findSubIndex("last4") or die "$!";
The last important note: when aggregating with multiple indexes, always use the sibling index types forming the same group or their nested sub-indexes (since the actual order is defined by the first leaf sub-index anyway). But don't use the random unrelated index types. If you do, the context would return some unexpected values for those, and you may end up with endless loops.